Storage medium characteristics deeply influence database system design. Traditional DBMS design assumed a two-tier hierarchy: high-speed low-capacity volatile storage (DRAM) and low-speed high-capacity non-volatile storage (SSD/HDD). The emergence of NVM breaks this assumption and may cause profound changes to DBMS design.
This paper adopts DRAM/NVM/SSD with in-place writes. In a classic DRAM/SSD two-tier hierarchy the buffer manager makes two decisions: which pages to cache and when. The most famous formulation is Jim Gray's Five Minute Rule (SIGMOD 1987). With a three-tier hierarchy it must additionally decide where to move pages.
Buffer Management in a DBMS: the replacement policy governs which frames are evicted.DBMS中的缓冲区管理:置换策略决定驱逐哪些帧。DBMSにおけるバッファ管理:置換ポリシーがどのフレームを退避するかを決定する。
II. Prior Work: HYMEM
二、先前工作:HYMEM
II. 先行研究:HYMEM
HYMEM [SIGMOD 2018] is the first buffer manager designed for DRAM/NVM/SSD. It distributes pages by access frequency: hot → DRAM, warm → NVM, cold → SSD. HYMEM implements two optimizations on top of a clock-based migration strategy:
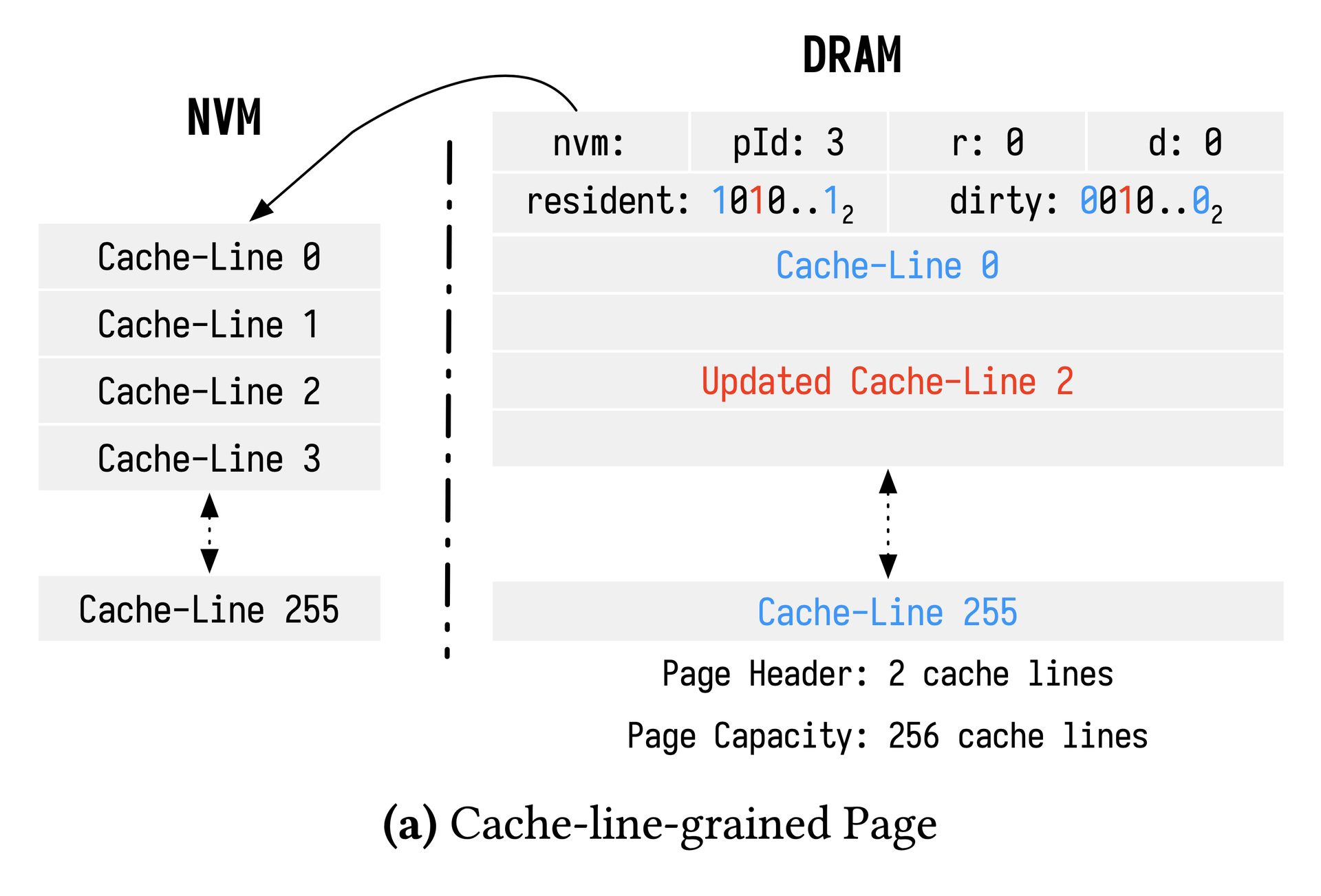
Cache-line-grained pages: Loads NVM pages into DRAM at cache-line granularity, exploiting NVM byte addressability. DRAM maintains resident and dirty bitmaps per page.
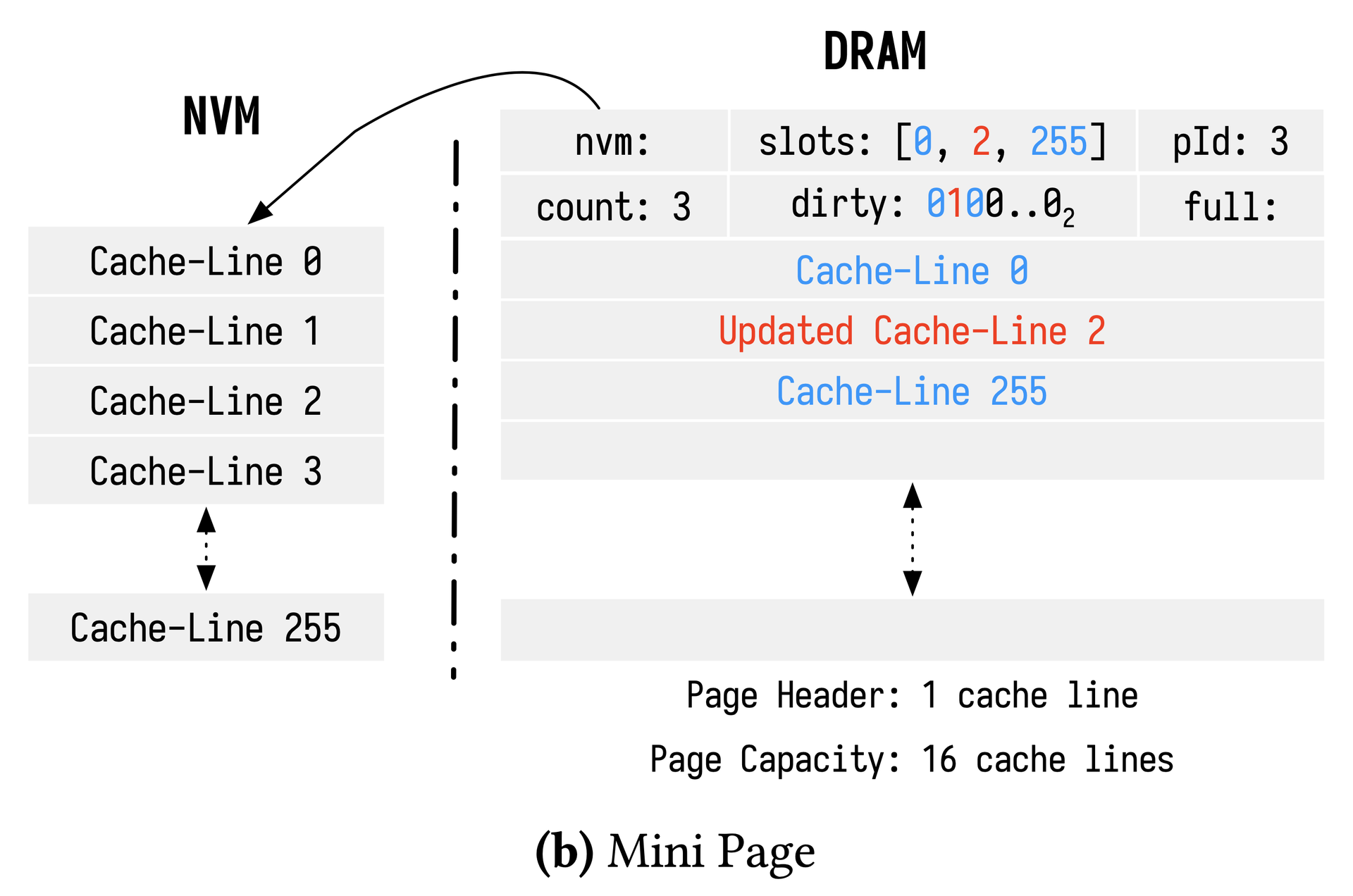
Mini-pages: A compact form capped at 16 cache lines; auto-upgraded to a full page when the count exceeds 16, reducing DRAM waste from sparsely populated pages.
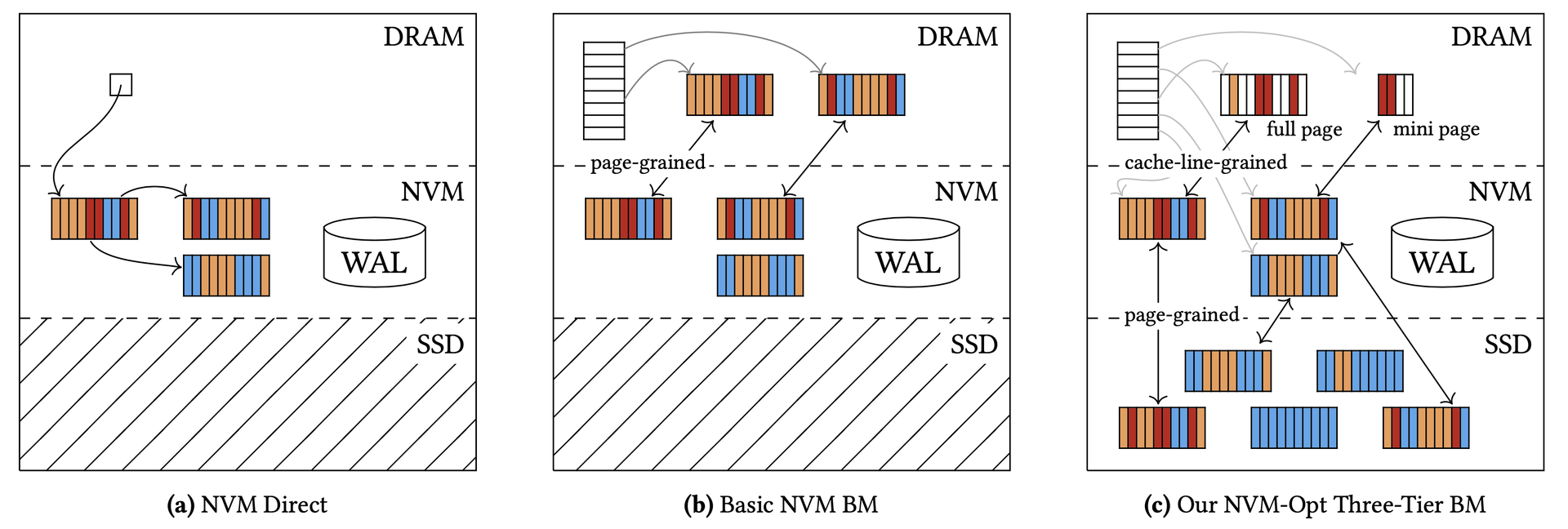
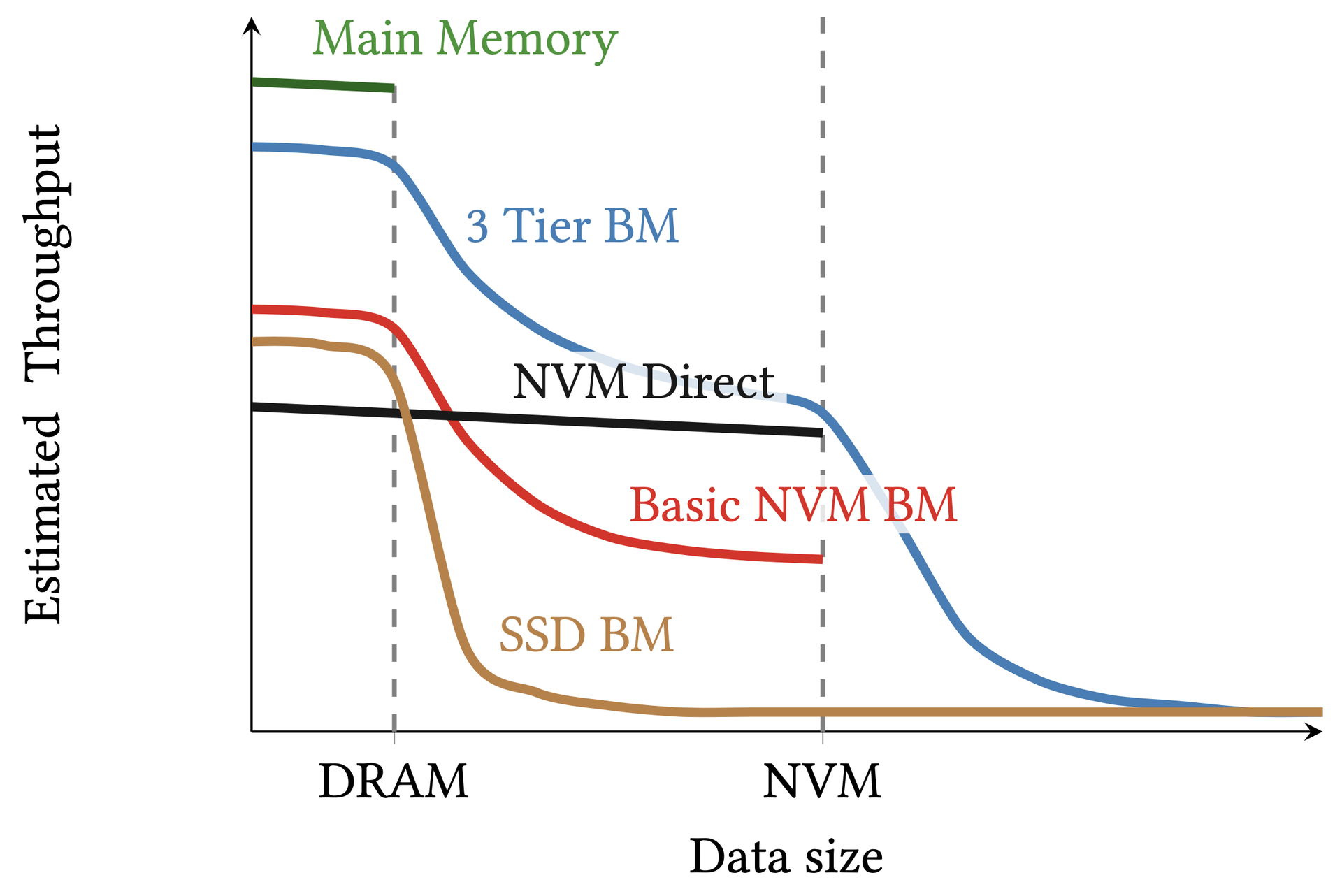
(a) NVM Direct — all data on NVM; (b) Basic NVM BM — page-grained loading; (c) Our NVM-Opt Three-Tier BM — cache-line-grained loading with mini-pages.(a)NVM Direct——数据全在NVM上;(b)Basic NVM BM——页粒度加载;(c)本文的NVM-Opt三层BM——缓存行粒度加载与小页面。(a)NVM Direct — 全データをNVMに; (b) Basic NVM BM — ページ粒度ロード; (c) NVM-Opt三層BM — キャッシュライン粒度ロードとミニページ。Estimated throughput across architectures as data size grows past DRAM then NVM capacity.数据大小分别超过DRAM和NVM容量时各架构吞吐量的估算比较。データサイズがDRAM・NVM容量を超えるにつれた各アーキテクチャの推定スループット。
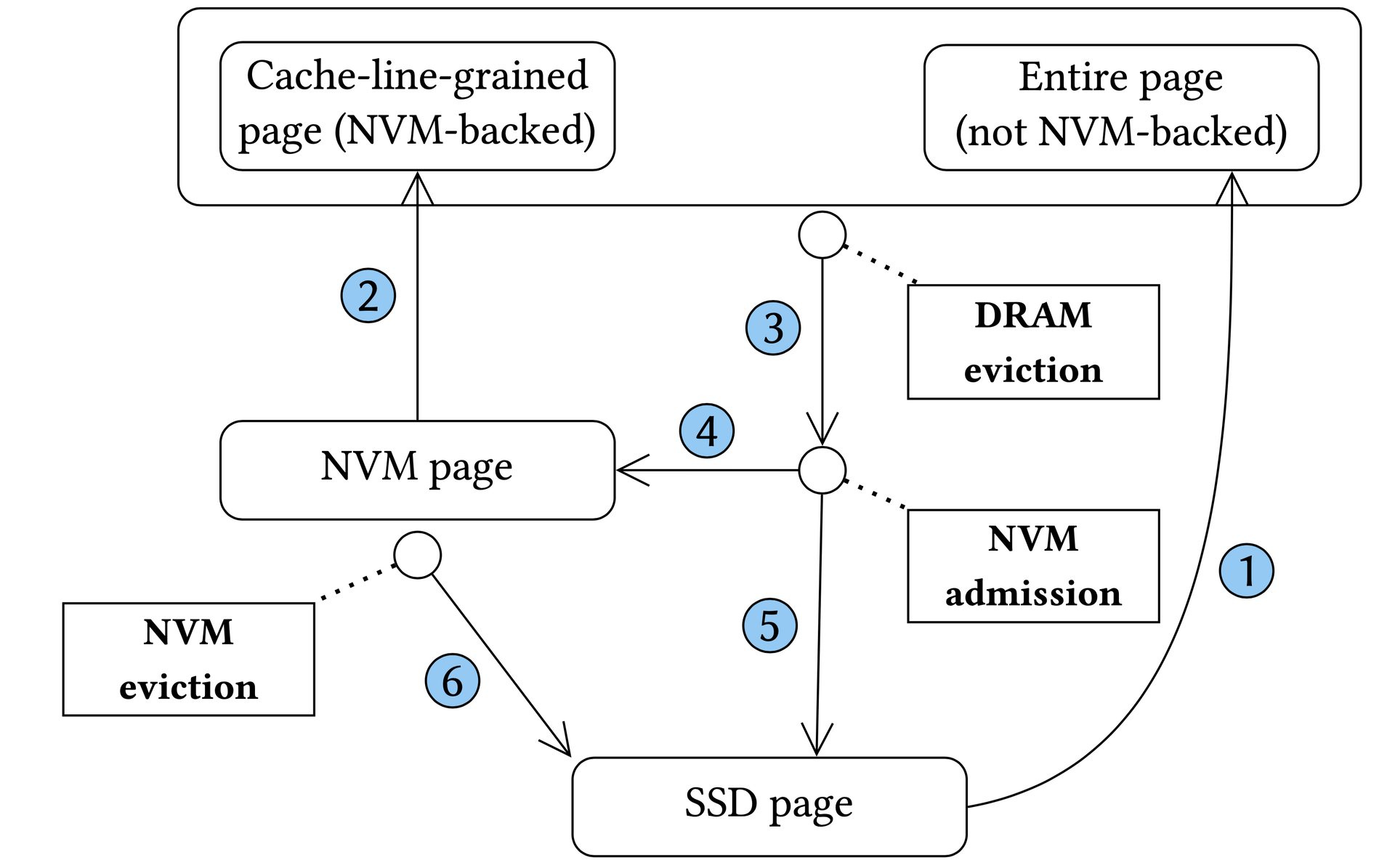
HYMEM's migration policy has five data transfer paths and three critical decisions:
HYMEM的数据迁移策略包含五条数据传输路径和三个关键决策:
HYMEMの移行ポリシーは5つのデータ転送パスと3つの重要な決定で構成されます:
Page absent from both DRAM and NVM → read from SSD into DRAM (path 1).
DRAM eviction: clock (second-chance) when DRAM is full.
NVM admission: use Admission Queue — not in queue → evict to SSD and enqueue (path 3→5); in queue → evict to NVM (path 3→4). Only pages evicted twice enter NVM.
Page in NVM, not DRAM → load at cache-line granularity into DRAM (path 2).
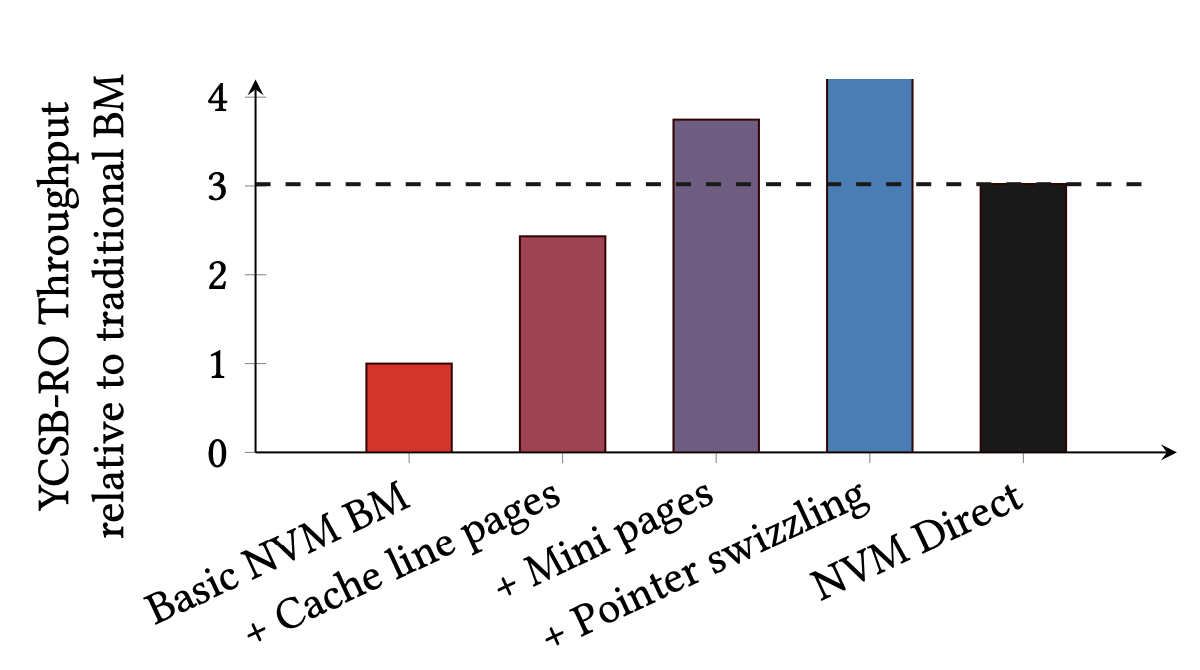
HYMEM page state transition diagram showing all six migration paths.HYMEM页面状态转移图,展示全部六条迁移路径。HYMEMのページ状態遷移図(6つの移行パスすべてを示す)。(a) Cache-line-grained Page: DRAM tracks which cache lines from an NVM page are resident and dirty.(a)缓存行粒度页面:DRAM记录NVM页面中哪些缓存行已载入(resident)以及是否被修改(dirty)。(a)キャッシュライン粒度ページ:DRAMがNVMページのどのキャッシュラインがresidentかdirtyかを追跡する。(b) Mini Page: a compact form with capacity 16, recording resident cache lines via a slots array.(b)小页面(mini-page):容量为16的压缩形式,通过slots数组记录已载入的缓存行。(b)ミニページ:容量16のコンパクト形式。slotsアレイで存在するキャッシュラインを記録する。YCSB-RO throughput relative to traditional BM, showing cumulative effect of each HYMEM optimization. With all optimizations HYMEM surpasses NVM Direct.相对传统BM的YCSB-RO吞吐量,展示HYMEM各项优化的累积效果。叠加全部优化后HYMEM超越NVM Direct。従来BM比のYCSB-ROスループット、HYMEMの各最適化の累積効果。全最適化を加えるとNVM Directを超える。
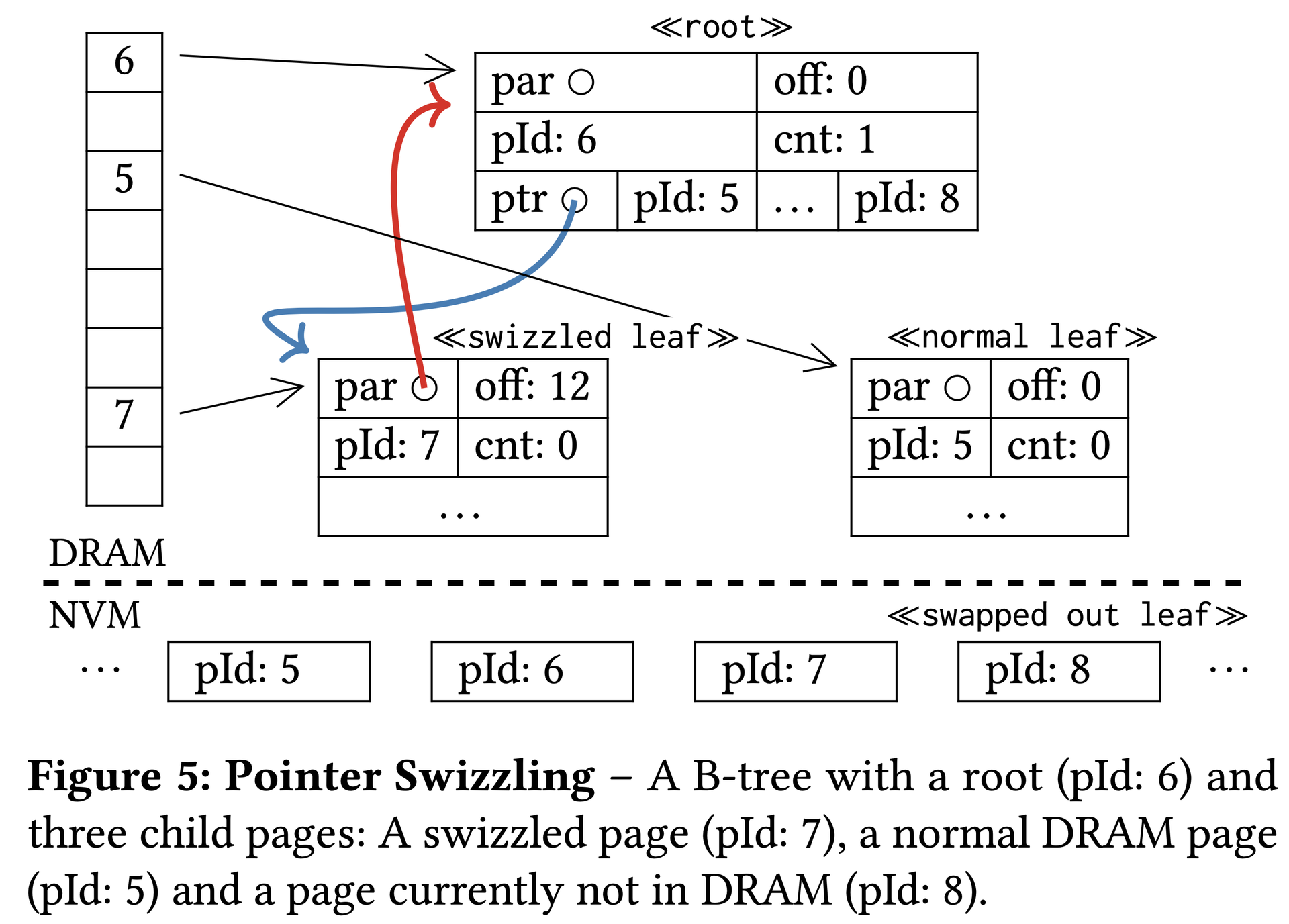
HYMEM also uses pointer swizzling — replacing page identifiers in DRAM with direct pointers to reduce page-table lookup overhead. However, HYMEM has several known limitations: (1) SSD→NVM and NVM↔CPU direct paths are absent, causing data duplication; (2) SSD→DRAM loading easily evicts hot pages; (3) single-threaded, no concurrency support.
Figure 5: Pointer Swizzling — a B-tree with a swizzled leaf (pId: 7), a normal DRAM leaf (pId: 5), and a swapped-out leaf (pId: 8).图5:指针换用——B树中一个已换用叶节点(pId:7)、一个普通DRAM叶节点(pId:5)和一个已换出叶节点(pId:8)。図5:ポインタスウィズリング — スウィズルされたリーフ(pId: 7)、通常のDRAMリーフ(pId: 5)、スワップアウトされたリーフ(pId: 8)を持つBツリー。
III. NVM-Aware Data Migration Policy: A Taxonomy
三、NVM感知数据迁移策略分类
III. NVM対応データ移行ポリシーの分類
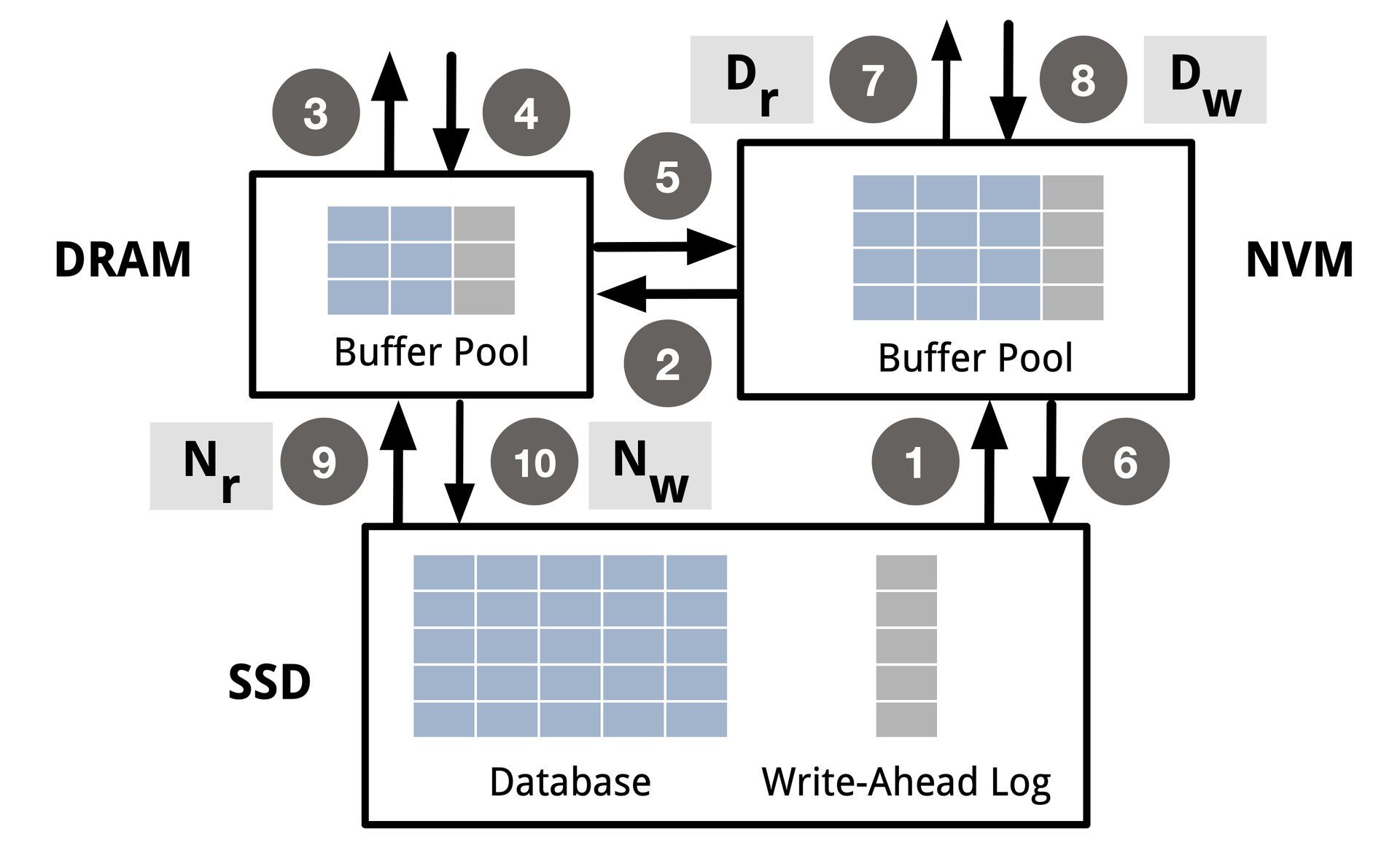
Spitfire enables all possible data flows and defines a 4-tuple to probabilistically characterize migration policies:
All ten possible data migration paths in the DRAM/NVM/SSD hierarchy.DRAM/NVM/SSD层次结构中所有十条可能的数据迁移路径。DRAM/NVM/SSD階層における10の可能なデータ移行パスすべて。
P = ⟨Dr, Dw, Nr, Nw⟩
Notation
Definition
Complement
Interpretation
Dr
P(NVM → DRAM)
1 − Dr
P(NVM → CPU)
Dw
P(CPU → DRAM)
1 − Dw
P(CPU → NVM)
Nr
P(SSD → NVM)
1 − Nr
P(SSD → DRAM)
Nw
P(DRAM → NVM)
1 − Nw
P(DRAM → SSD)
Each parameter is implemented via random sampling of access history. A hot NVM page accessed N times is promoted to DRAM with probability 1 − (1 − Dr)N → 1 as N → ∞. Semantic interpretation:
Dr: Probability of promoting an NVM page to DRAM on read. Use larger Dr when the working set fits in DRAM; smaller otherwise.
Dw: Probability that a CPU write goes to DRAM. Smaller Dw exploits the NVM↔CPU path and avoids evicting hot DRAM pages.
Nr: Probability that an SSD miss loads into NVM (vs. directly into DRAM).
Nw: Probability that a DRAM eviction writes through NVM before SSD. Analogous to HYMEM's Admission Queue, but probabilistic. Smaller values reduce NVM wear.
Spitfire tunes P adaptively using simulated annealing with cost function cost(P) = 1/T (inverse throughput). Starting at high temperature for broad exploration and cooling gradually, it converges to the global optimum with high probability.
Algorithm 1: Data Migration Policy Tuning via Simulated Annealing.算法1:基于模拟退火的数据迁移策略调整。アルゴリズム1:模擬焼きなまし法によるデータ移行ポリシー調整。
Two reference policies:
两个参考策略:
2つの参照ポリシー:
Policy
Dr
Dw
Nr
Nw
HYMEM
1
1
0
AdmQueue
Spitfire-Eager
1
1
1
1
Spitfire-Lazy
0.01
0.01
0.2
1
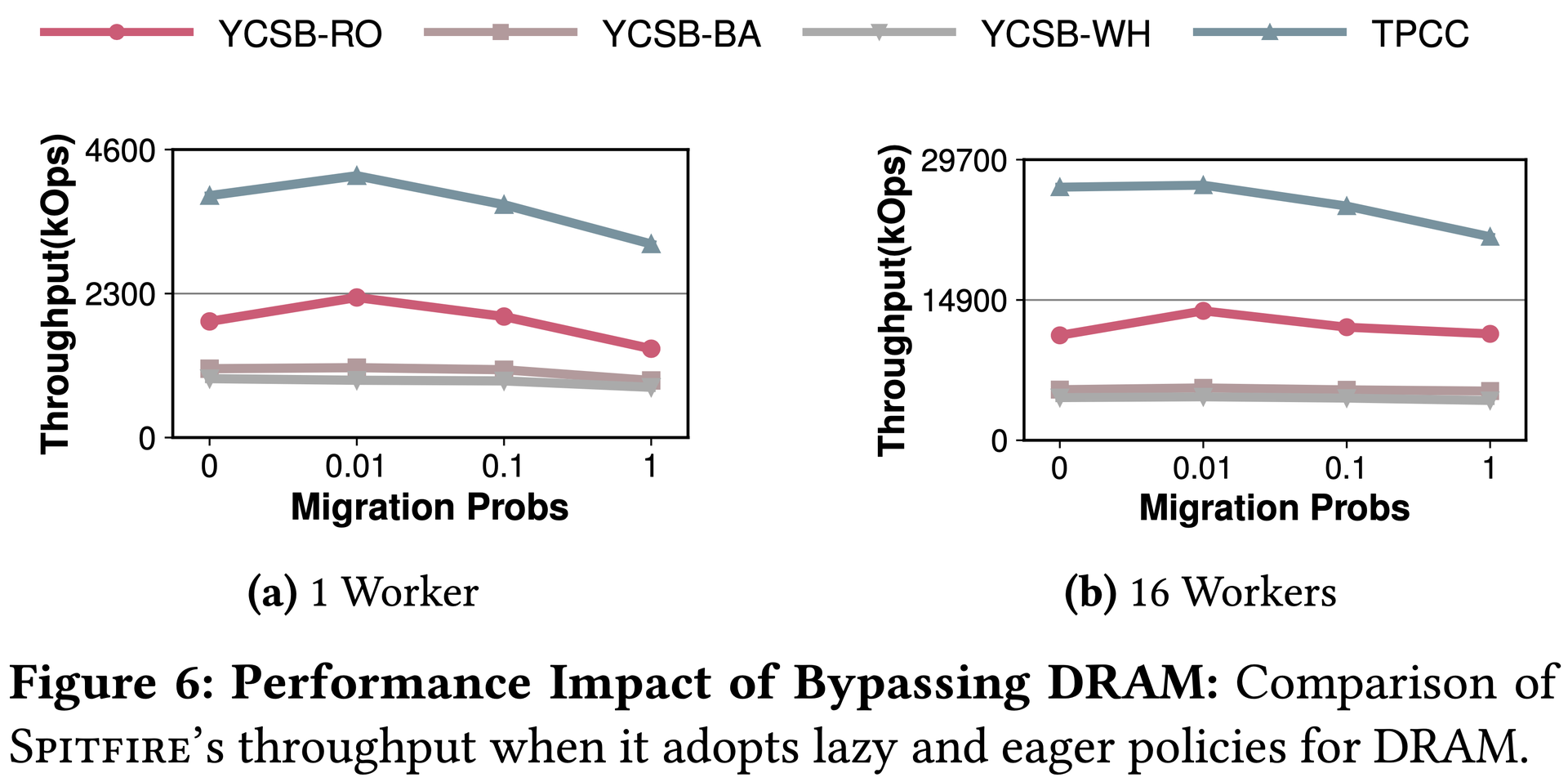
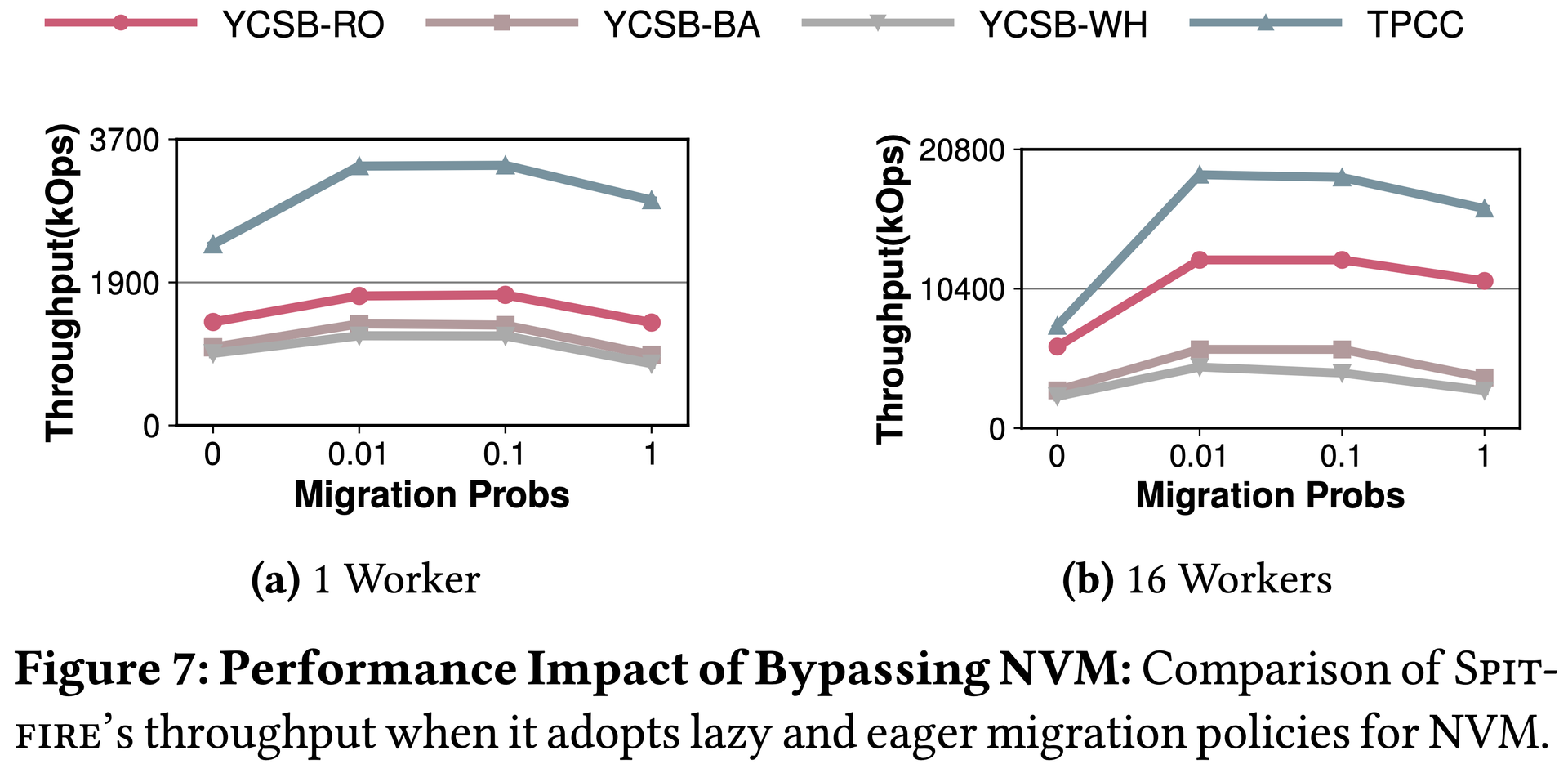
Eager always follows SSD→NVM→DRAM→CPU reads and CPU→DRAM→NVM→SSD writes. Lazy routes most NVM accesses directly to CPU (Dr=Dw=0.01), reads most SSD misses into DRAM (Nr=0.2), and writes all DRAM evictions directly to SSD (Nw=1), protecting NVM.
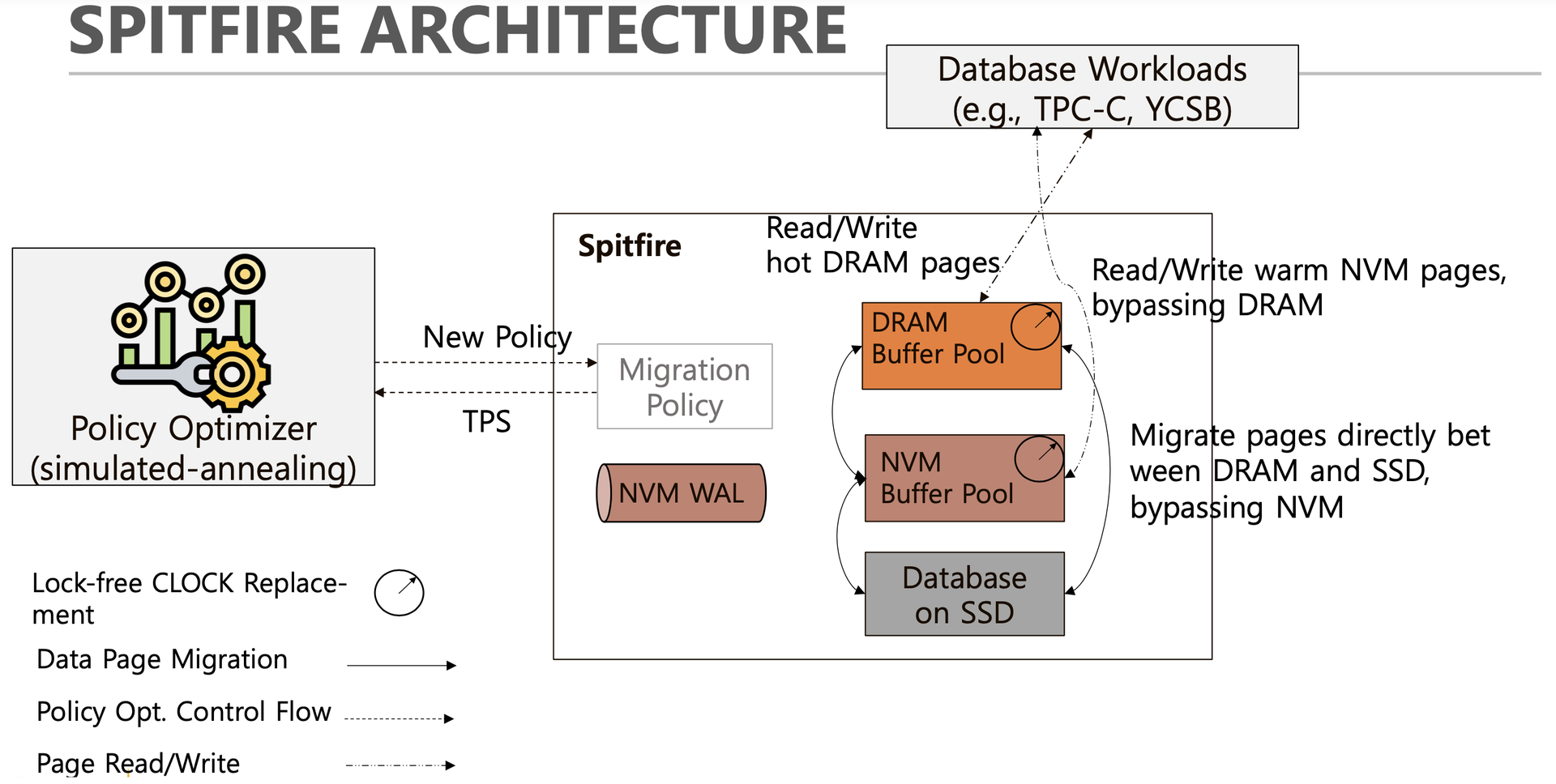
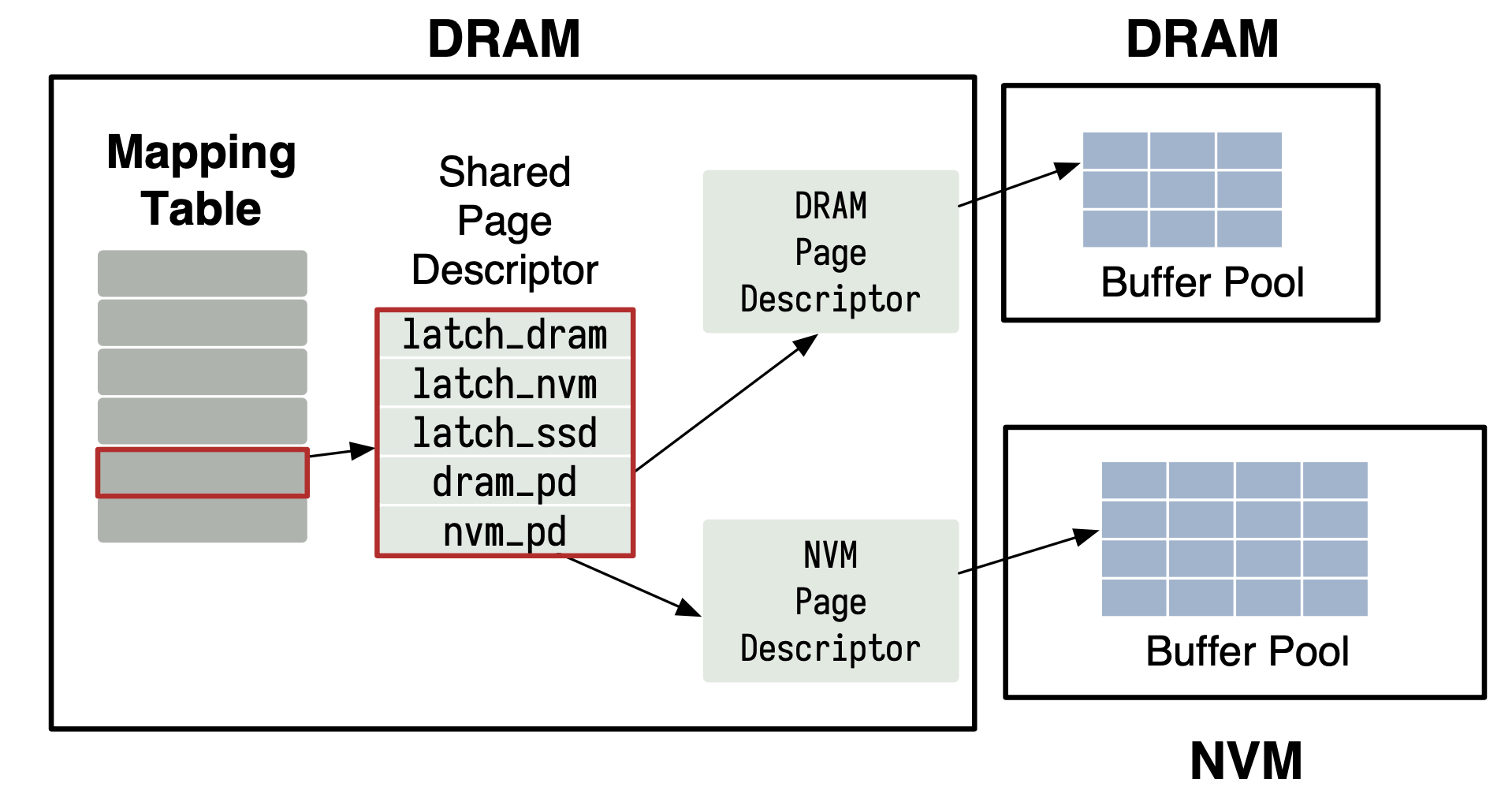
Spitfire maintains a concurrent hash table (mapping table) in DRAM storing per-tier latches and page descriptors. On a page request: page in DRAM → return DRAM frame; page in NVM and bypass permitted → return NVM frame directly; page absent → load per migration policy. Eviction uses clock. Inter-tier migration requires holding both tiers' latches simultaneously.
Mapping Table: each entry holds latch_dram, latch_nvm, latch_ssd and pointers to DRAM/NVM page descriptors.映射表:每条记录包含latch_dram、latch_nvm、latch_ssd以及DRAM/NVM页面描述符的指针。マッピングテーブル:各エントリにlatch_dram、latch_nvm、latch_ssdとDRAM/NVMページ記述子へのポインタを保持する。
Spitfire additionally uses a concurrent bitmap for migration tracking, MVTO for concurrency control, and a concurrent B+Tree with optimistic lock coupling for indexing. The WAL is implemented in NVM. On restart, Spitfire scans NVM to find latest page versions, rebuilds the mapping table, then executes standard DBMS recovery (analysis, redo, undo).
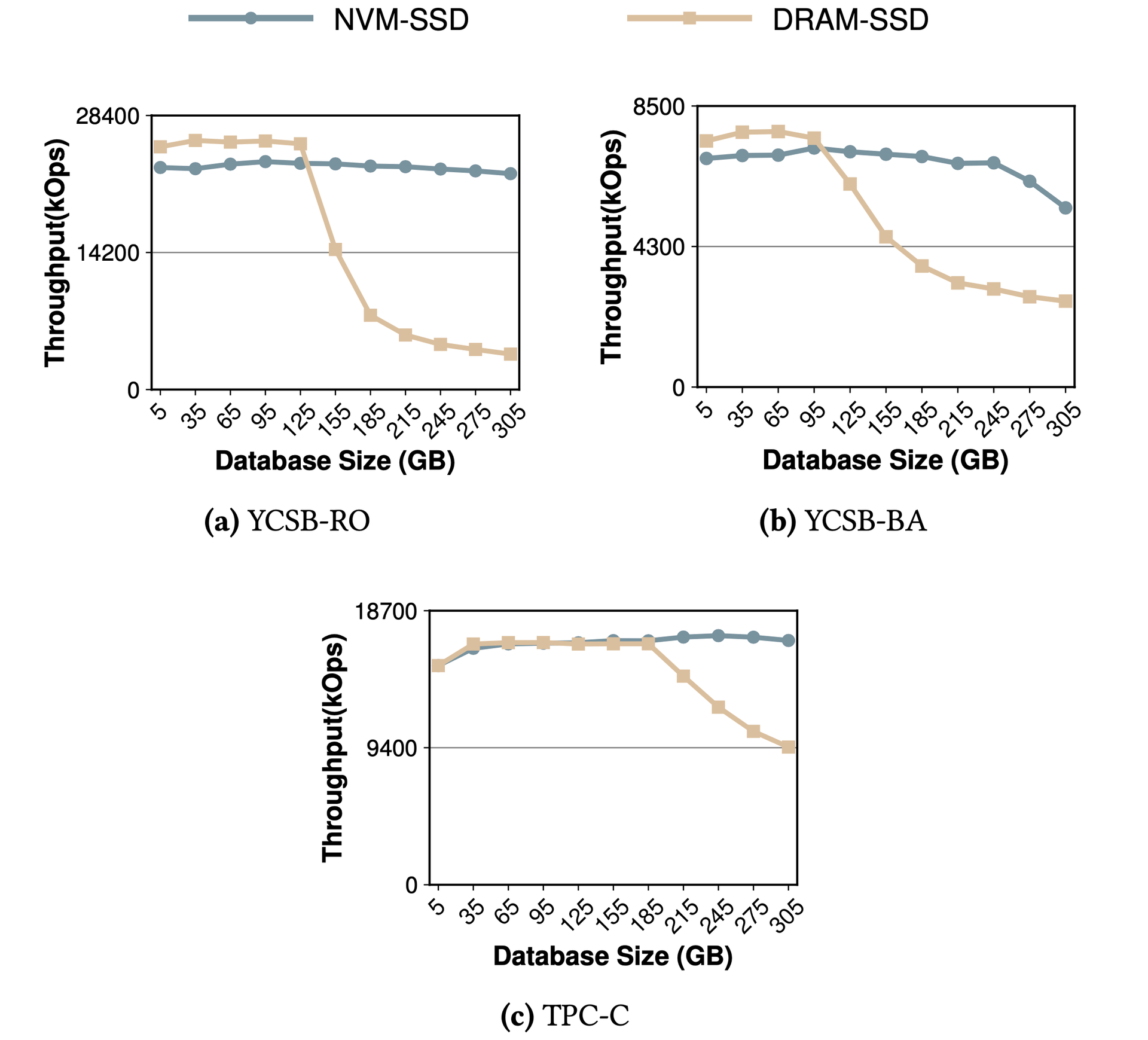
Throughput of NVM/SSD vs. DRAM/SSD at equal cost. As write ratio increases the gap narrows — NVM avoids dirty-page-flush overhead.相同成本下NVM/SSD与DRAM/SSD的吞吐量比较。随写入比例增加差距收窄——NVM避免了脏页刷盘开销。同コストでのNVM/SSDとDRAM/SSDのスループット比較。書き込み比率が増加するにつれてギャップが縮小 — NVMはダーティページのフラッシュオーバーヘッドを回避する。
Optimal Migration Policy per Workload
不同工作集下的最优数据迁移策略
ワークロードごとの最適移行ポリシー
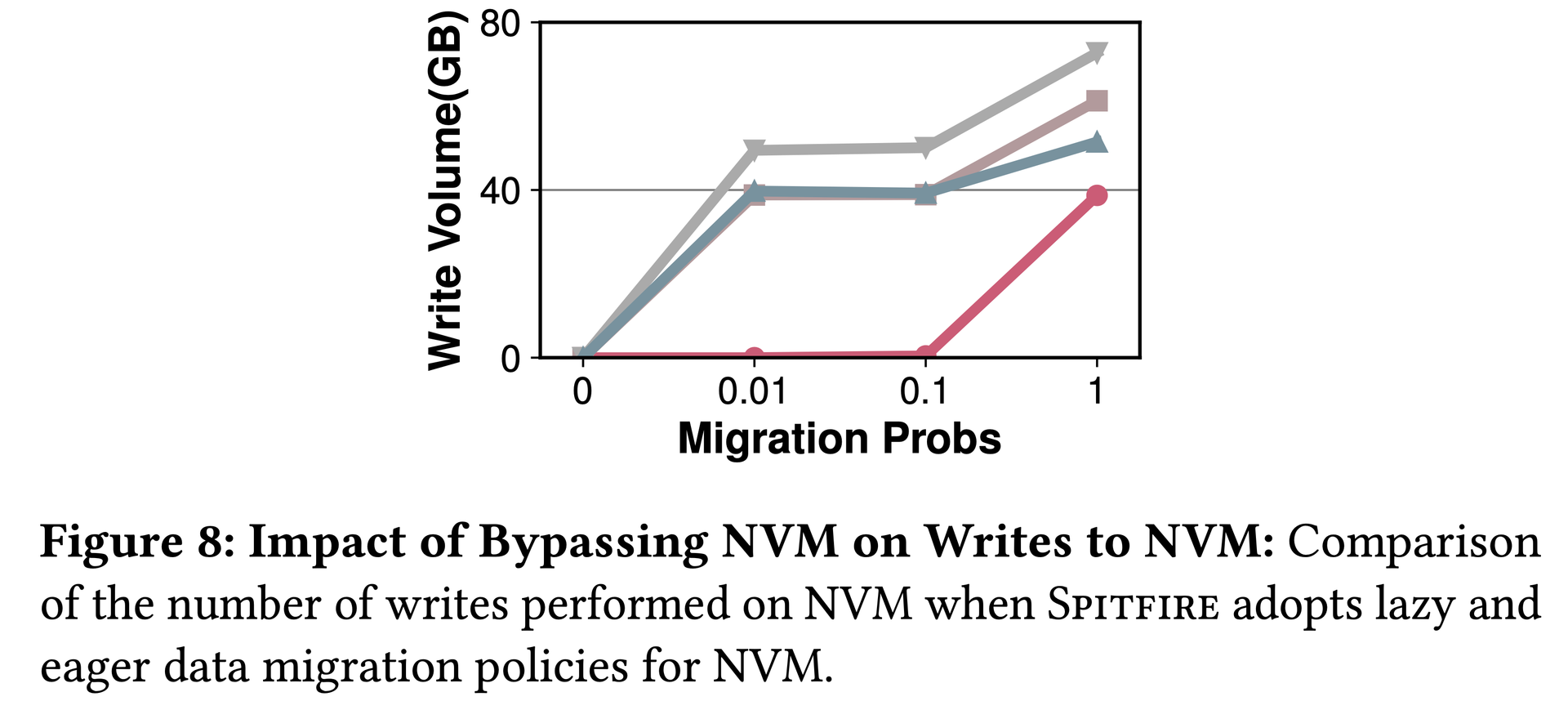
Figure 6: D = 0.01 (lazy) is optimal. D = 0.01 outperforms D = 1 by 58% on YCSB-RO: it reduces DRAM/NVM duplication 16×, ensures only frequently-accessed data reaches DRAM, and maximizes effective cache size.图6:D=0.01(lazy)在所有负载下均最优。YCSB-RO下D=0.01比D=1性能高58%:减少DRAM/NVM数据重复16倍,确保只有常访问数据进入DRAM,最大化有效缓存空间。図6:D=0.01(lazy)がすべてのワークロードで最適。YCSB-ROではD=0.01がD=1より58%高い:DRAM/NVM重複を16倍削減し、頻繁にアクセスされるデータのみDRAMに到達させ、有効キャッシュサイズを最大化する。Figure 7: N = 0.01 is optimal. Setting N = 0 hurts more than D = 0 because NVM capacity ≫ DRAM capacity.图7:N=0.01最优。设置N=0的影响远大于D=0,因为NVM容量远大于DRAM容量。図7:N=0.01が最適。NVM容量≫DRAM容量のため、N=0の設定はD=0より大きなダメージを与える。Figure 8: Lazy strategy significantly reduces NVM write volume, extending NVM device lifetime.图8:Lazy策略显著减少NVM写入量,延长NVM设备使用寿命。図8:Lazyストラテジーはすることでデバイス寿命を延ばす。NVMの書き込み量を大幅に削減する。
Simulated Annealing Convergence
模拟退火的收敛性
模擬焼きなまし法の収束
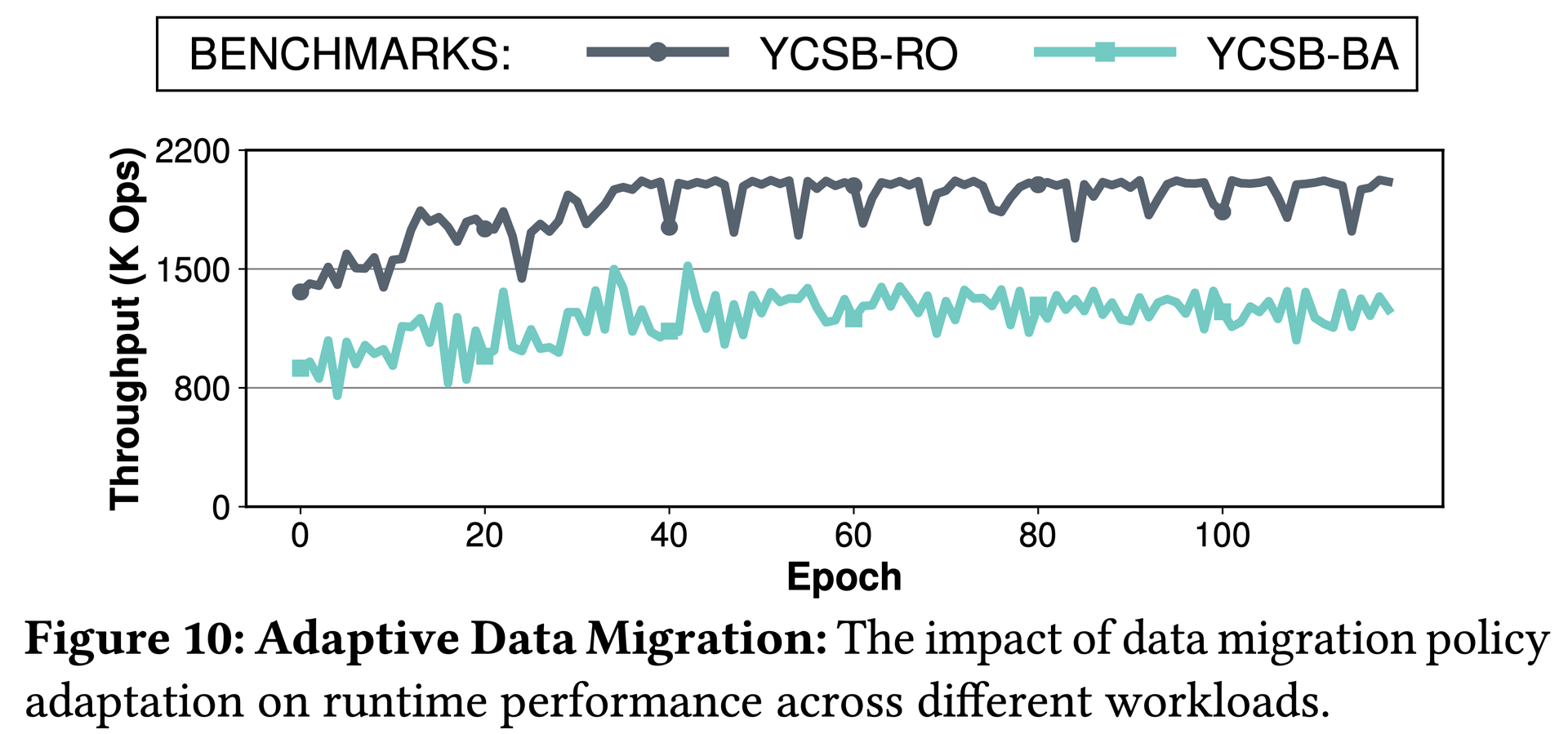
Figure 10: Simulated annealing converges to near-lazy policy within ~40 epochs on both YCSB-RO and YCSB-BA.图10:模拟退火在约40个epoch后收敛至接近lazy的策略(YCSB-RO和YCSB-BA均如此)。図10:模擬焼きなまし法はYCSB-ROとYCSB-BAの両方で約40エポック以内にlazyポリシーに近い状態に収束する。
HYMEM vs. Spitfire
HYMEM与Spitfire对比
HYMEM対Spitfire
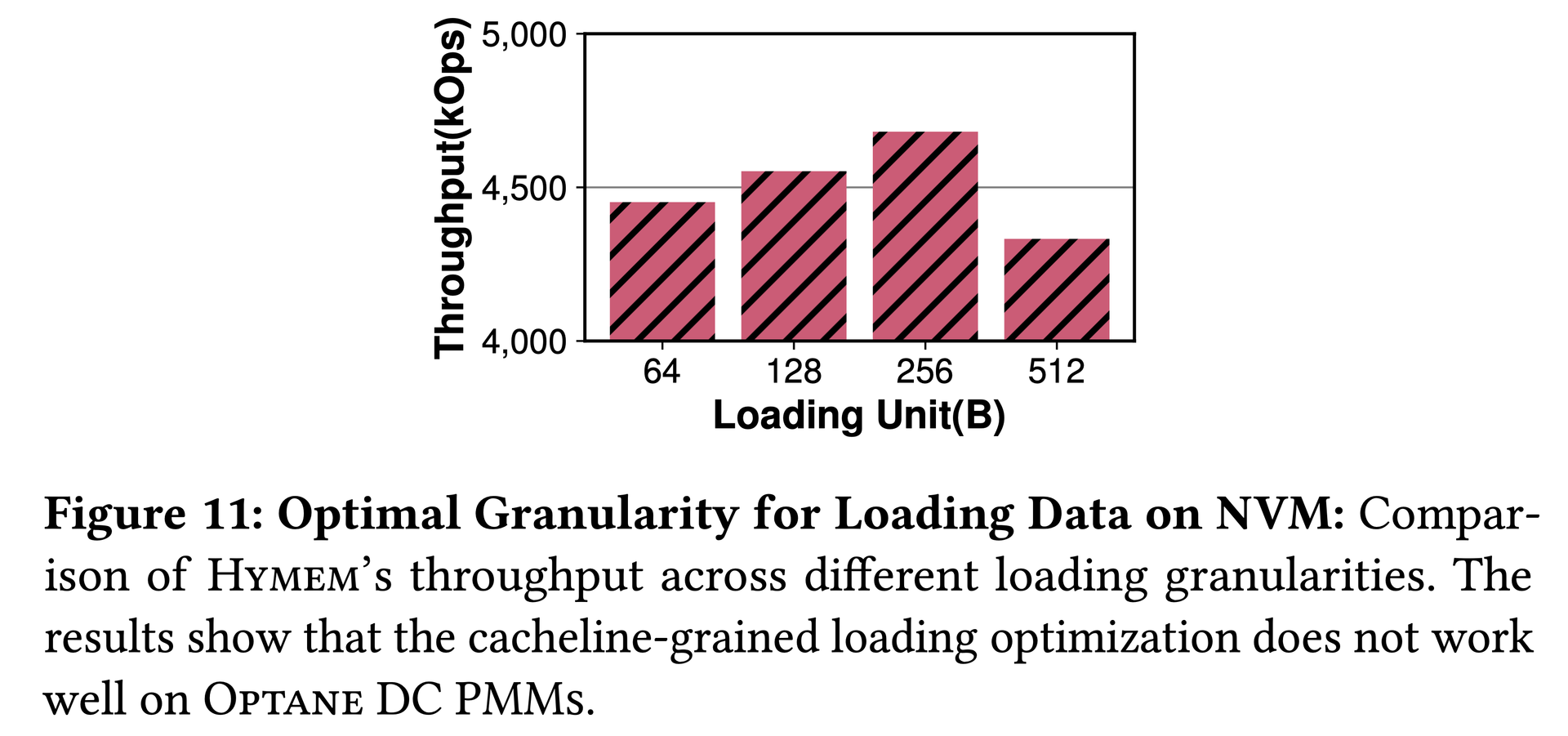
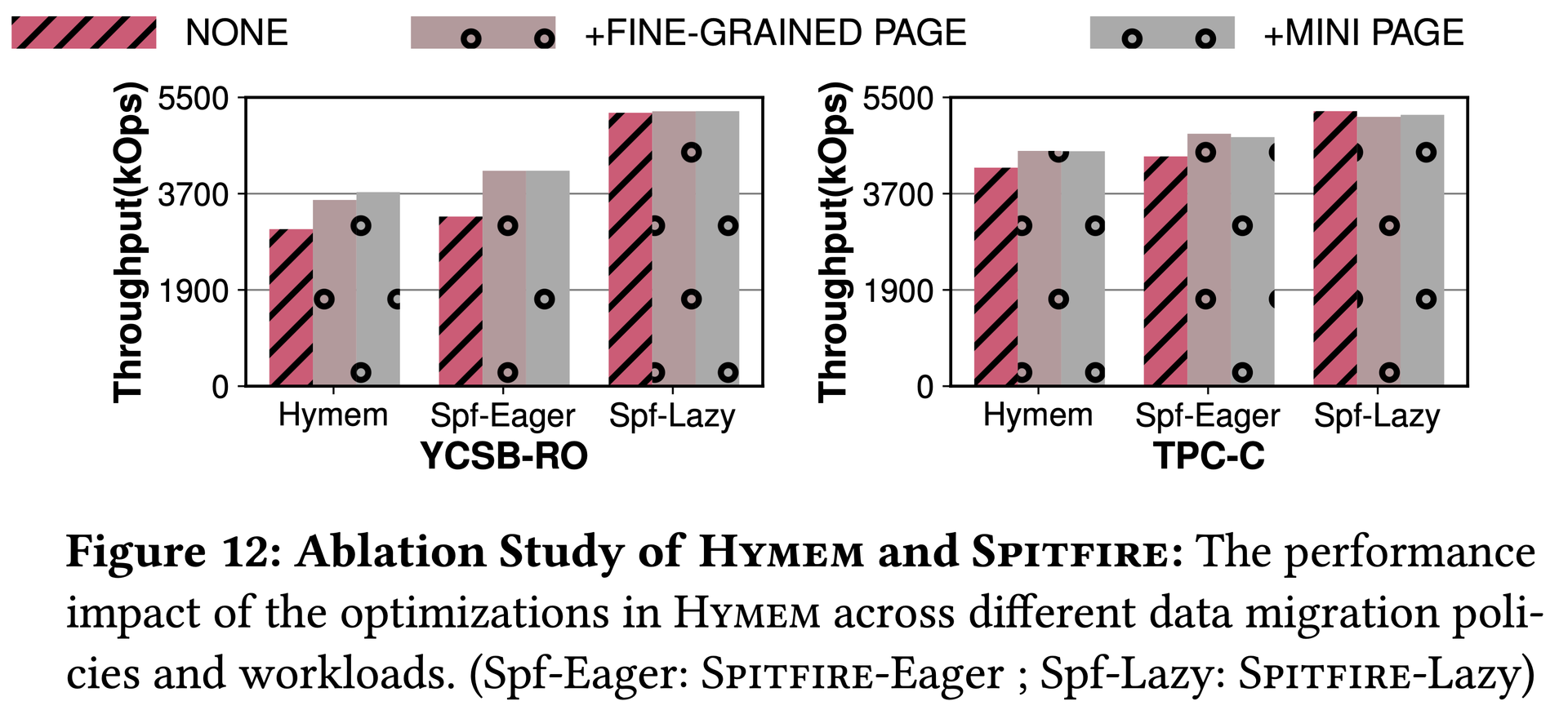
Figure 11: Optimal NVM loading granularity is 256 B on Optane DC PMMs, not HYMEM's assumed 64 B.图11:Optane DC PMMs上的最优NVM数据加载粒度为256B,而非HYMEM假设的64B。図11:Optane DC PMMs上の最適NVMロード粒度は、HYMEMが想定する64Bではなく256Bである。Figure 12: Spitfire-Lazy significantly outperforms HYMEM — migration policy choice dominates over fine-grained loading optimizations.图12:Spitfire-Lazy显著超越HYMEM——迁移策略的选择比细粒度加载优化对性能的影响更大。図12:Spitfire-LazyがHYMEMを大幅に上回る — 移行ポリシーの選択が細粒度ロード最適化より支配的。
We demonstrate that the choice of the migration policy is more important than the fine-grained loading and mini-page optimizations. — Spitfire
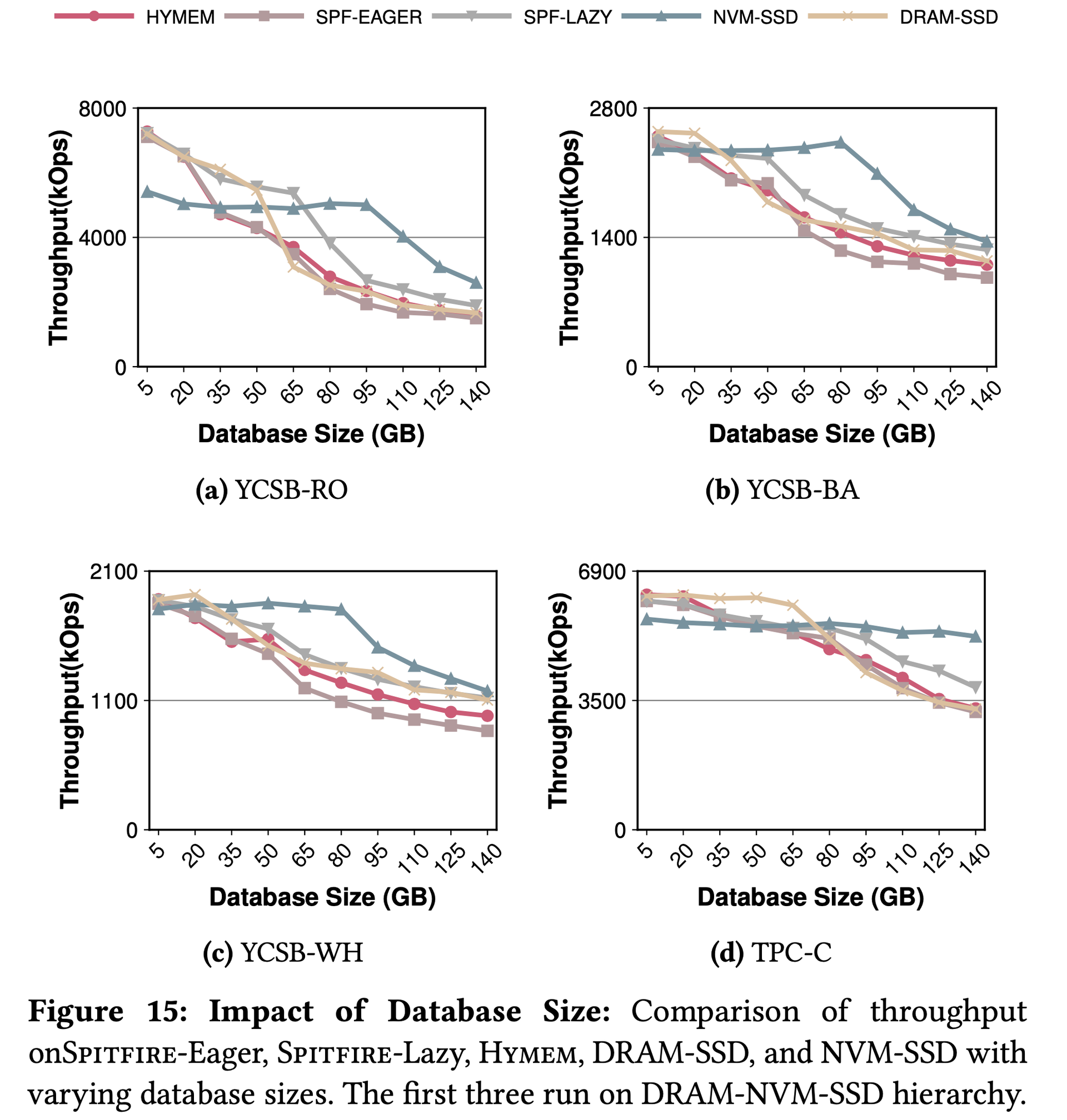
Figure 15: Spitfire-Lazy leads on DRAM/NVM/SSD for read-heavy and small workloads; NVM/SSD leads for write-heavy and large workloads.图15:读密集型或小工作集下Spitfire-Lazy在DRAM/NVM/SSD上表现最佳;写密集型或大工作集下NVM/SSD更优。図15:読み取り集中型・小規模ワークロードではSpitfire-LazyがDRAM/NVM/SSDでリード;書き込み集中型・大規模ワークロードではNVM/SSDがリード。
Three storage architecture design principles: (1) For maximum absolute performance, architecture must include DRAM. (2) For read-intensive workloads, DRAM/NVM/SSD achieves the best performance/price ratio. (3) For write-intensive workloads, NVM/SSD is best — NVM persistence reduces recovery overhead.
HYMEM, the first DBMS buffer manager for DRAM/NVM/SSD, achieves performance beyond NVM Direct via clock-based hot/warm/cold page distribution and NVM byte-addressability optimizations. Spitfire introduces a probabilistic vector representation of migration policies enabling simulated annealing-based workload adaptation. Its key finding: migration policy selection dominates performance, outweighing fine-grained cache-line and mini-page optimizations. The Spitfire-Lazy policy consistently outperforms HYMEM across diverse workloads.